TL;DR we ran the test at scale, looked for shortcuts, and the machine kept its promise. Full writeup below.
01The question
We know that for MD5 : change one input bit, and roughly half the output bits flip, unpredictably. I didn't want to take that on faith. If you fix the first character of a password, every sample starts with A does any trace of that survive into the hash or is seen in the hash? . Just a whisper. A single bit, byte, or hex digit anything which we could detect.
That's a testable, so we that's what I tried to find.
02Method
Generate large batches of random passwords with one feature held constant i.e first character, length 7 .. hash each with MD5, then bucket the outputs and check whether any bucket deviates from what pure chance predicts.
We ran this at increasing scale on lightning.ai first with 3,000 samples per letter, then 50,000 then 1,000,000 per letter across all 26 letters 26 million hashes in the final pass, bucketed by the first hex digit of the output.
We didn't stop at one run. A real correlation should survive a change of random seed.Every test was re-run with a fresh seed before anything got called a finding.
03The full sweep
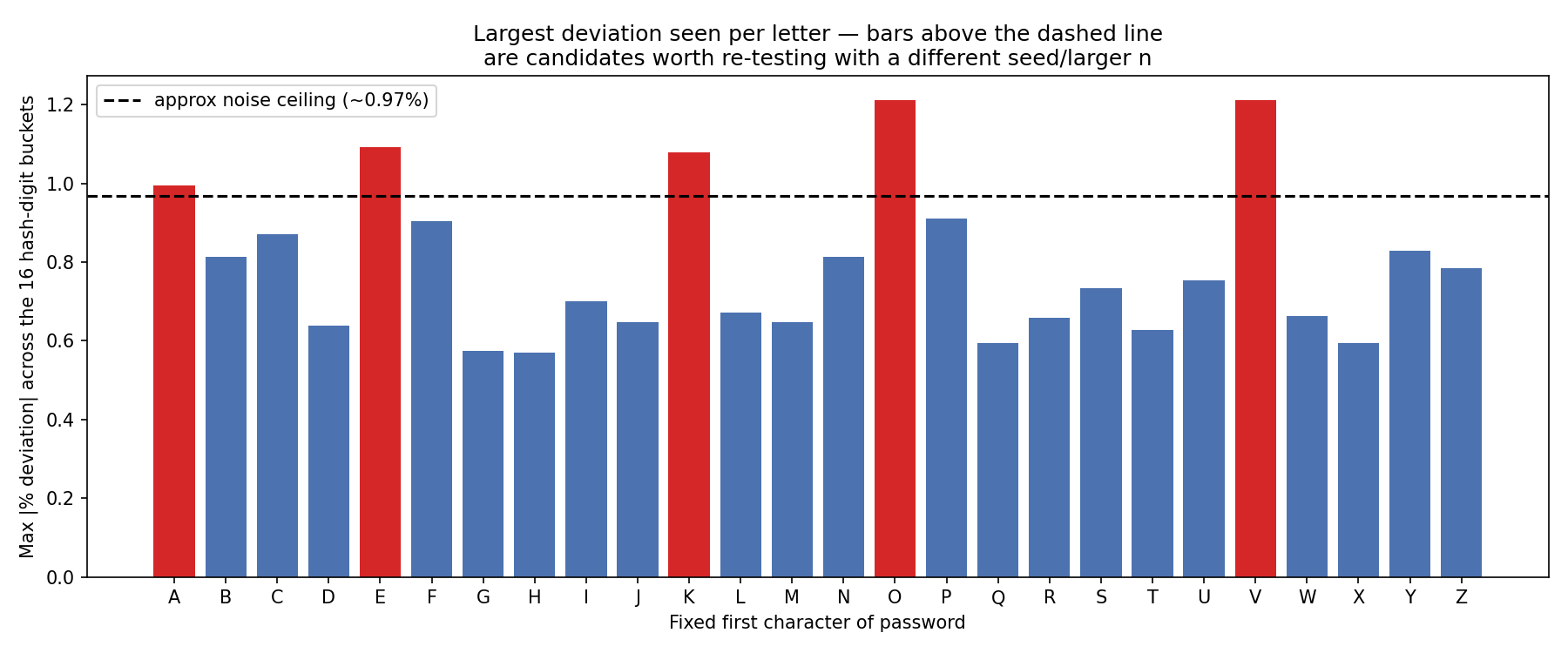
One bucket isn't a thorough test, so we expanded to a 26×16 grid every letter A–Z fixed as the first character, against every possible first hex digit of the resulting hash visualized as a single heatmap.
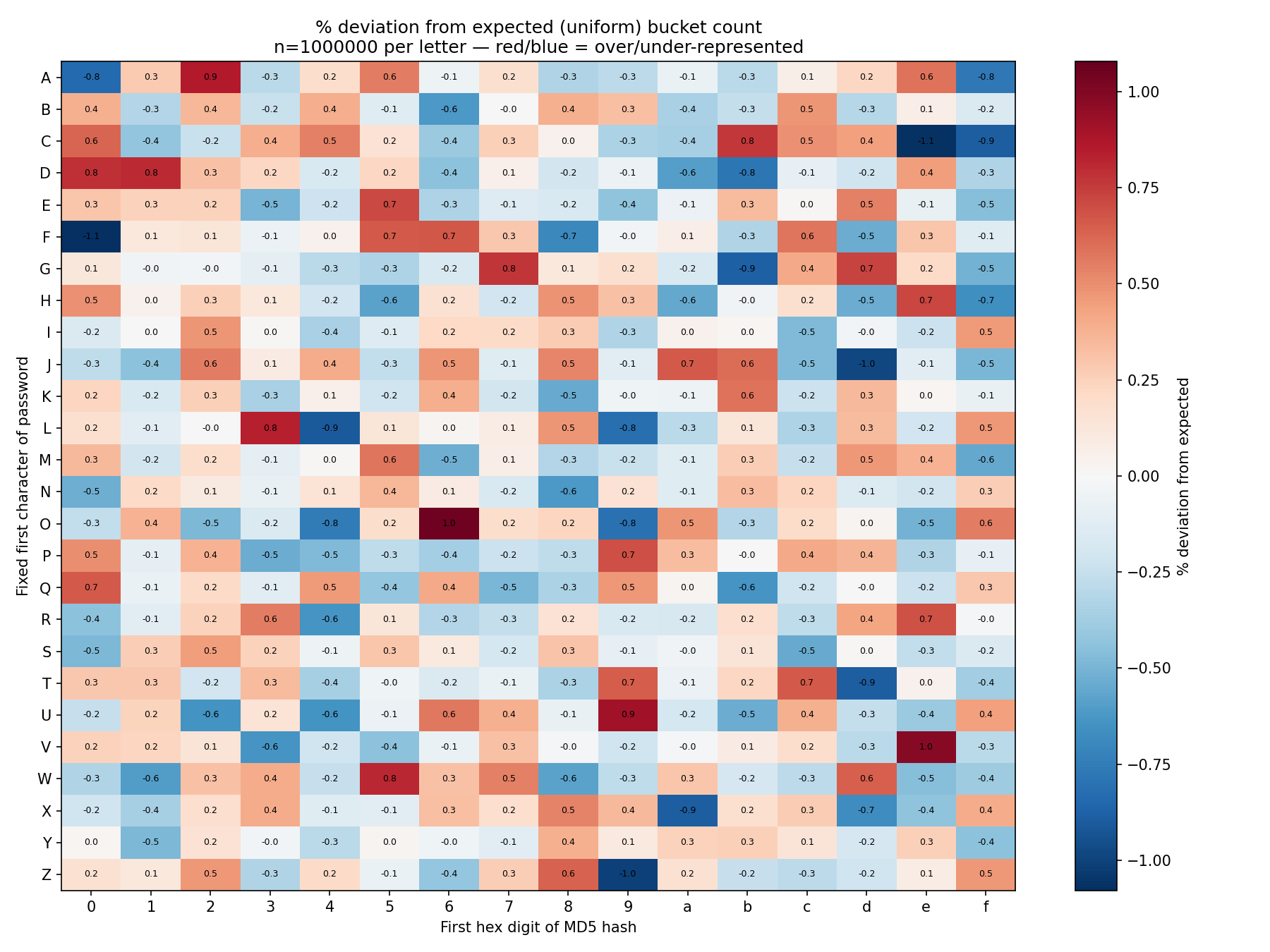
If the bias were real, one whole row or column in the heatmap would stay the same color.
At small sample sizes, individual letters crossed our significance threshold first B and D, then a different set entirely once we reseeded. That instability is the tell:
| Seed | n / letter | Letters flagged | Max deviation |
|---|---|---|---|
| 42 | 1,000,000 | A, E, K, O, V | 1.21% |
| 41 | 1,000,000 | E, F, P | 1.05% |
Only E repeated. Across 26 independent letters and a ~1–2% per-letter false-positive rate at our threshold, that's exactly the overlap you'd expect from chance alone, not a pattern holding its shape.
04Findings
No statistically reproducible correlation was found between the first character of a fixed-length password and any single hex digit, byte, or sampled bit of its MD5 digest, across 27 million hashes and multiple independent random seeds. Every apparent "hit" failed to survive a reseed.
This matches what differential and linear cryptanalysis predict about MD5's compression function: 64 steps of nonlinear mixing, modular addition, and misaligned bit rotation are enough to make a single input character's influence statistically indistinguishable from noise by the time it reaches the output.
I've only tested first-character vs. first-hex-digit. Last character, middle occurrences, repeated-character patterns, and bit-level (not hex-digit-level) mutual information are still untested at this scale. That's next ambition or the project direction.
05What's next — this is Part 1
This is the first post in a series. We've only tested one narrow slice: first character vs. first hex digit. Part 2 widens the grid — last character vs. last digit, character position vs. specific output bytes, and a full 128-bit mutual-information sweep. We'll run all these tests together and apply one combined statistical check across all of them .
Part 2 — coming soon.